 2022年5月のJava Silverに引き続き、Java Gold(正式名称 Oracle Certified Java Programmer, Gold SE 11)に合格しました!
「Java Gold」の範囲を横断的にまとめたサイトがあまり無いようでしたので、勉強法と合わせて学んだことを記していきたいと思います。
2022年5月のJava Silverに引き続き、Java Gold(正式名称 Oracle Certified Java Programmer, Gold SE 11)に合格しました!
「Java Gold」の範囲を横断的にまとめたサイトがあまり無いようでしたので、勉強法と合わせて学んだことを記していきたいと思います。
Java Silverも同様の記事をまとめていますので、こちらもご参照ください。
準備期間と結果
準備期間は2022年5月7日~9月4日と約4か月でした。
結果は正解率:86%で合格することが出来ました!

合格までの勉強法
1.問題集(黒本)
Java Silverと同じなのですが、「徹底攻略 Java SE 11 Gold問題集」、通称黒本をしっかり理解できればJava Goldには合格できます。 実際の試験でも3~4割は黒本とほぼ同じ問題が出題されている印象でした。 問題→解説と進めていけば順序立ててに知識を広げていけるよう出題の順番も練られていて、非常に理解しやすいです。 しかし黒本はあくまで問題集なので、例えばメソッド一覧のような体系的な情報が無く、知識が断片的になりがちだと感じます。そこを次に紹介する紫本でフォローしていくイメージです。
![徹底攻略Java SE 11 Gold問題集[1Z0-816]対応](https://m.media-amazon.com/images/I/51IRfIxlTEL._SL500_.jpg "徹底攻略Java SE 11 Gold問題集[1Z0-816]対応")
2.参考書(紫本)
こちらもJava Silverと同様「オラクル認定資格試験教科書 Java プログラマ Gold SE 11」、通称紫本を使いました。 体系立てて説明しているので、黒本で断片化した知識を整理する役割を担います。ただし文章がやや取っつきにくい印象があるので、先に黒本で問題を解いて知識の土台を作ってから紫本を読み解くのが効率的だと思います。
")
3.試験内容チェックリスト
Oracle公式の試験内容チェックリスト(リンクはこちら)は、黒本で知識が深まってきたタイミングで一度目を通しておくとよいです。
熟読する必要はないですが「このインターフェース、メソッドってチェックリストに出るくらい大切なんだ」と重要ポイントに気付けると思います。

今回学んだこと
ではJava Goldの試験範囲を整理していきます。
メソッドの引数、戻り値等の詳細情報は紫本・黒本を見れば正確に書いてあるので、ここでは私が重要と思ったポイントの「考え方・概念」をまとめます。
「この機能ってこういう意味なのね」と取っ掛かりが作っていただき、そこから先は参考書・問題集で詳細な知識を深めてもらえればと思います。
これ以降の章立ては黒本に準拠しています。
クラスとインターフェース
①ネストクラス
Silverには無かった概念として、クラスやメソッドの中に定義するクラス(=ネストクラス)があります。
ネストクラスの種類は、大きく分けて以下4つです。
 特にインナークラスとstaticインナークラスは、エンクロージングクラスの外から次のように呼び出されてインスタンス化されます。
staticインナークラスはエンクロージングクラスをあらかじめnewでインスタンス化しておかなくてもよい、というのが違いです。
特にインナークラスとstaticインナークラスは、エンクロージングクラスの外から次のように呼び出されてインスタンス化されます。
staticインナークラスはエンクロージングクラスをあらかじめnewでインスタンス化しておかなくてもよい、というのが違いです。
new Outer().new Inner(); //インナークラスの場合 new Outer.StaticInner(); //staticインナークラスの場合
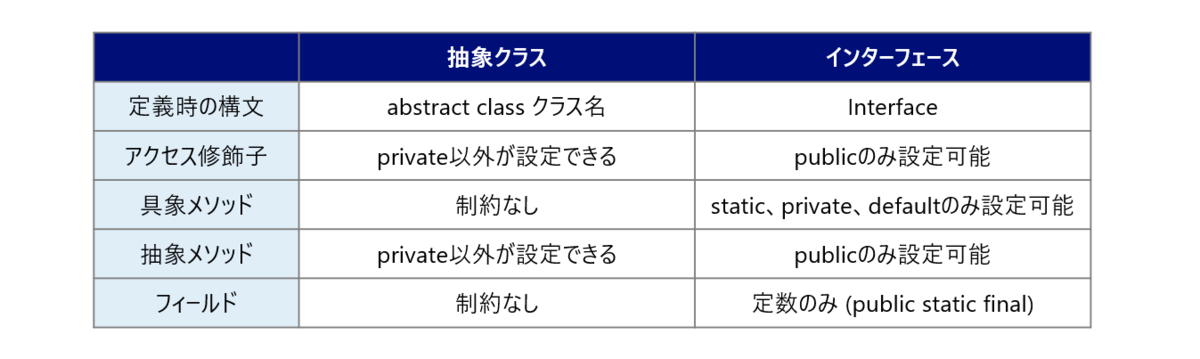
②インターフェースの定義
ここはSilverの範囲と重複します。
インターフェースに定義できるフィールドやメソッドの制約を理解し、試験では「このinterfaceはpublicな具象メソッドがあるからコンパイルエラーだな」という風に解きます。
③列挙(Enum)型
列挙型は定数を定義するための仕組みで、次のように定義します。
public enum Sports { SUCCER, BASEBALL, BASKETBALL, TENNIS; }
用途はSwitch文の分岐や、メソッドの引数指定です。 例えば下記の様なコードにすれば、Switch文を1、2、3のような初見で意味が分からない値で分岐させるよりも可読性・保守性が高まります。
int players; Sports type = Sports.SUCCER; //playerに11が設定される switch(type) { case SUCCER: players = 11; break; case BASEBALL: players = 9; break; case BASKETBALL: players = 5; break; case TENNIS: players = 1; break; }
Enumは内部的にはクラスとして定義されるので、コンストラクタやフィールド、メソッドの定義も可能です。
並列処理
②Executorによるスレッドプール
③排他・同期処理
①Threadクラス
並列処理とは「マルチスレッド」で行う処理のことです。
従来の順繰りメソッドを実行していく「シングルスレッド」とは違い、複数処理を同時実行することで性能向上が見込めます。
そのマルチスレッドな環境を作るのがjava.lang.Threadクラスです。
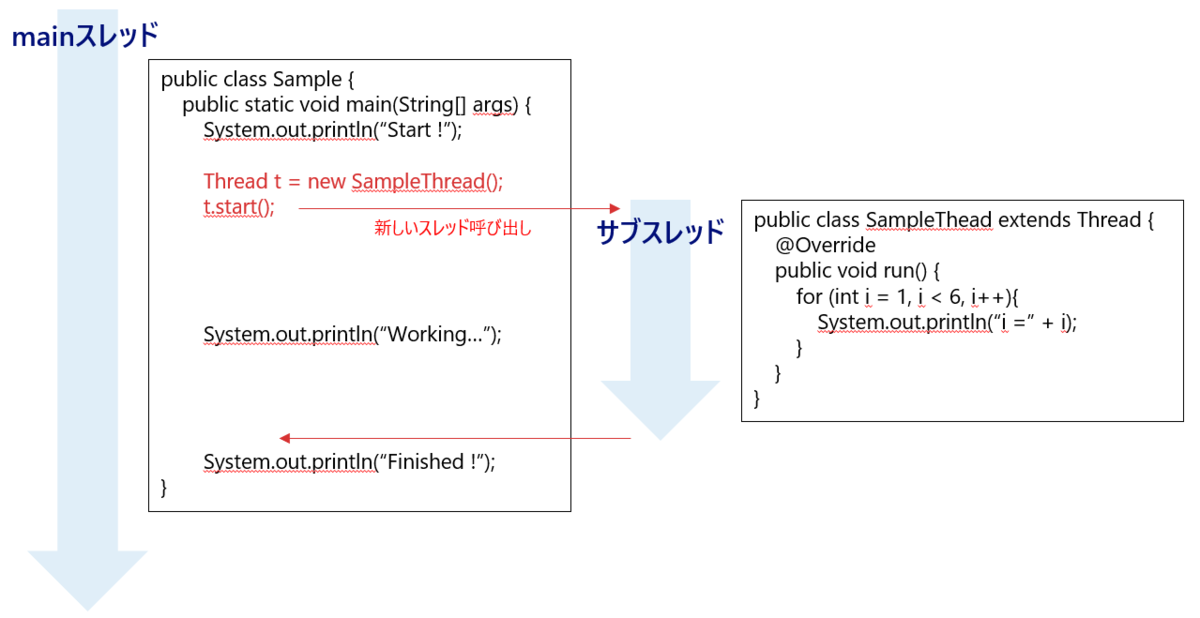
Threadクラスのstartメソッドで新しいスレッドを作ります。 そのスレッドでrunメソッドに動かしたい実処理をオーバーライドして定義します。 runメソッドは明示的に起動する必要はなく、startメソッドがスレッドを作成した後、JVMの方が良きタイミングで自動実行してくれます。
上図のコードを実行すると次のような結果になります。 ただし、mainスレッドとサブスレッドはそれぞれ独立して動くので実行する度に表示順序は変わる可能性があります。
> java Sample Start ! i = 1 i = 2 Working... i = 3 i = 4 Finished ! i = 5
②Executorによるスレッドプール
スレッド作成(Threadクラスのstartメソッド)はかなり負荷が高い処理です。
なのでスレッドは使い捨てるのではなく、あらかじめスレッドを作成しておき、みんなで使い回すほうがより効率的です。
その「あらかじめ作成しておいたスレッド」のことをスレッドプールと呼びます。
スレッドプールを司るのがExcecutorsクラスとExecutorインターフェースです。

newFixedThreadPool()メソッドがスレッドプールを作成するstaticメソッドで、戻り値はExecutorService型です。
Executorインターフェースの実装しており、execute()メソッドを実行することで、引数のRunnable処理をスレッドプールの各スレッドで起動します。
また、Runnableインターフェースのrunメソッドは戻り値に何も返さない(void)ので、スレッド開始元になにか返したい場合はCallableインターフェースのcallメソッドを使います。
上図コードのtry文をCallableに置き換えてみます。
service = Excecutors.newSingleThreadExecutor();
Callable<Date> task = () -> new Date();
Future<Date> result = service.submit(task);
System.out.println(result.get());
2行目のCallableの型パラメータ
3行目でスレッドプールでのタスク実行メソッドがexecute()ではなくsubmit()になっていることに注意してください。
また、戻り値がFuture型になっています。
Futureオブジェクトはスレッドプールのタスクが完了したかどうかのチェック、タスク結果の取得などのメソッドを持っています。
4行目でそのメソッドの1つであるget()を使ってDate型の結果を取得しています。この場合、Sun Sep 4 10:30:00 JST 2022のような結果が得られます。
③排他・同期制御
独立して動くスレッドの順番を制御するのが同期制御であり、それを実現する1つの方法がjava.util.concurrent.CyclicBarrierクラスです。
また、複数スレッドで同じオブジェクトに対して参照・更新する処理の場合、「スレッドAが参照している間にスレッドBが値を更新して不整合を起こした」ということがあり得ます。他のスレッドに邪魔されないようオブジェクトを一時的に独占することを排他制御と呼び、synchronizedキーワードを使います。
排他・同期制御ともに具体的な実装方法は割愛しますが、どちらもマルチスレッド特有の要件に基づく制御方式なのでまずはその目的と概要を抑えてください。
ストリームAPI
①ストリームAPI
Java Goldで最も出題率が高いと思われるパートです。
ストリームAPIは、配列やCollectionを便利に扱えるようにした拡張機能です。
これを使うことで、配列やCollectionに対して「全要素を一括変換」「全要素の合計・平均の導出」「条件に合った要素の検索」などが簡易に行えます。

ストリームAPIは「1. ストリームの生成」「2. 中間処理」「3. 終端処理」の順番に、対象の配列・コレクションにメソッドを連ねていきます。
この表記をストリームパイプラインと呼びます。
まずは「1. ストリームの作成」です。作成方法はストリームの元となるデータ型で異なります。
- 対象がリストなどのCollectionの場合、<対象のCollection>.stream()で生成
- 対象が配列の場合、Arrays.stream(対象の配列)で生成
- 対象がStringやInteger等の単一要素の場合、Stream.of(要素A, 要素B, ..., 要素Z)で生成
上図のString型のリストは、1つ目の方法であるlist.stream()でString型のストリームStream<String>を生成しています。
また、intやdoubleなどのプリミティブ(基本データ)型をストリームにすると、IntStreamやDoubleStreamという型になることにも注意です。
次は「2. 中間処理」です。 取り出した要素になんらかの処理を加えてストリームに戻す処理です。0個以上の中間処理を連ねることが出来ます。 例えば上図のlimit()は指定した数に要素を切り詰めた結果のストリームを戻します。 map()は引数に指定したFunction処理を要素に適用した結果のストリームを戻します。 他にもpeek()、skip()、sorted()などがあるので黒本・紫本に記載されている中間処理はすべて理解しておく必要があります。
最後は「3. 終端処理」です。 要素に対して施す最終的な処理で、StringやInterger等何らかのデータかvoidで終わります。 各ストリームに1つだけ指定でき、2つ以上指定するとillegalStateExceptionがスローされます。 上図だとforEach()が終端処理で、各要素に繰り返しConsumer処理を行います。
ストリームAPIにおけるポイントは、ストリームパイプラインで「今は何の型のストリームなのか」を読み解くことです。 中間処理を挟むとStream<String>がStream<Integer>、IntStreamなどに型が変換されていくことがあります。 変換を経て今は何の型になっているのかを意識し、呼び出されている中間処理や終端処理と整合がとれているかを確認しましょう。
②Optionalクラス
ここで一旦ストリームAPIから離れて、Optionalクラスについて触れます。
Optinalオブジェクトは単一の要素を保持する「ただの箱」なのですが、「nullや例外発生時は空の箱」にすることでOptionalを参照する側は例外処理を組まなくてよくなります。

Optionalクラスには値有り/無しの判定メソッド(isPresent)や、値の取得メソッド(get)等が用意されています。 なぜこのOptionalクラスをここで扱うかというと、ストリームAPIの終端処理のいくつかは戻り値がOptional型だからです。
③リダクション
終端処理にはリダクションという種類があります。リダクションとは要素に1つに「まとめる」操作のことです。
例えばストリームの要素の合計値を求めるsum()や、最大値を求めるmax()はリダクションです。
他にも任意のリダクション処理を実装できるreduce()やcollect()もあります。
例えばreduce()の基本形は次のようなコードです。引数にBinaryOperator型の処理を指定します。
Stream<Integer> stream = Stream.of(10, 20, 30); Optional<Integer> result = stream.reduce((a, b) -> a + b); // resultには60が入る
もしStream.of()のように空ストリームにするとreduce結果も空になりますが、戻り値がOptional型であることで上記ソースコードのまま例外処理を組まずに実装できます。
入出力
②入出力ストリーム
③NIO.2
①Decoratorパターン
オブジェクト指向プログラミングにはデザインパターンという扱いやすく再利用性が高いコーディングの23種類のパターンがあります。
そのうちの1つが「Decoratorパターン」です。
このパターンを使うと、既存クラスのメソッドの呼び出し方を変えずに機能を拡張させることが出来ます。
 Employee、DecoClassA、DecoClassBは全てPerson抽象クラスを継承しており、getName()メソッドを持っています。
最初は苗字を返すだけのメソッドだったのが、デコレーションクラスで包むことで姓名やミドルネーム付きで名前を返却するよう機能拡張させています。
名前の通り、デコレーションクラスを重ねることでメソッドを着飾っていくイメージです。
Employee、DecoClassA、DecoClassBは全てPerson抽象クラスを継承しており、getName()メソッドを持っています。
最初は苗字を返すだけのメソッドだったのが、デコレーションクラスで包むことで姓名やミドルネーム付きで名前を返却するよう機能拡張させています。
名前の通り、デコレーションクラスを重ねることでメソッドを着飾っていくイメージです。
コーディングではDecoClassA( Employee employee )のように、デコレーションクラスのコンストラクタ引数に基本クラスを渡すことで機能拡張させます。
このデザインパターン自体はJava Goldに出題されないのですが、次の入出力ストリームはDecoratorパターンを使って設計されているため、概念を把握しておくと理解しやすくなります。
②入出力ストリーム
ここでのストリームは「データの流れ」という意味で、ファイルやコンソールとのデータの入出力を扱います。
ストリームAPI(java.util.Stream)とは別物ですので注意してください。
まずは「入力ストリーム」です。
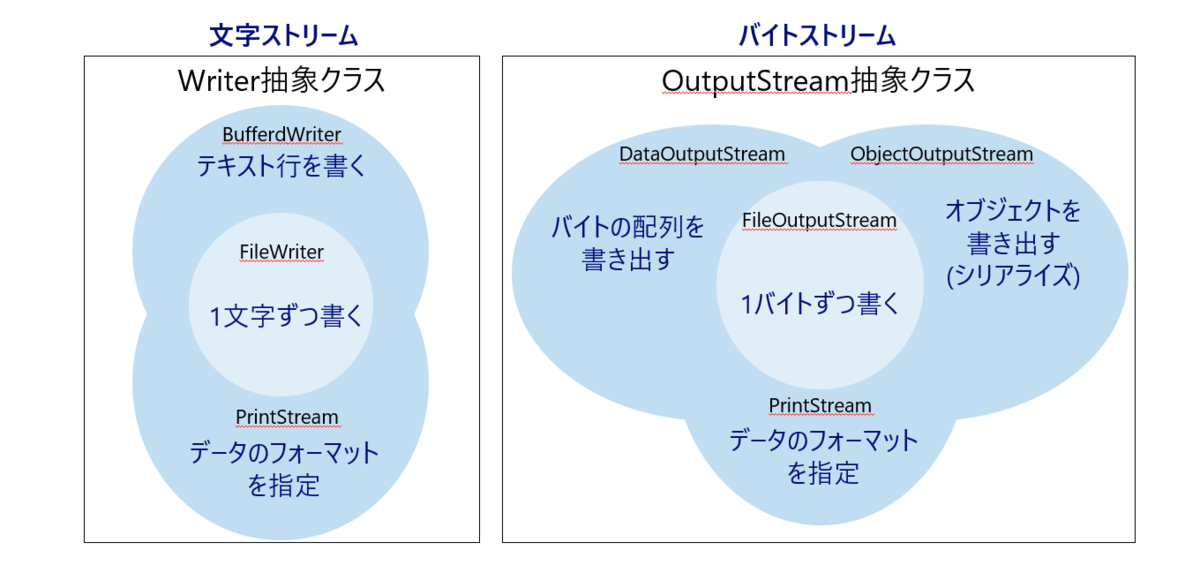
ベースの抽象クラスはReaderとInputStreamの2つで、前者がテキストファイル等の文字を扱い、後者は画像ファイル等のバイトコードを扱います。
基本クラスはFileReaderとFileInputStreamですがこれらの読取り処理は効率が悪いので、実際には上図のいずれかでデコレーションして使います。

次は「出力ストリーム」です。
ベースの抽象クラスはWriterとOutputStreamの2つで、こちらも前者が文字を、後者はバイトコードを扱います。
標準出力に文字列を表示させるときにSystem.out.println("test")のメソッドを良く使いますが、実はSystem.outはPrintStream型のオブジェクトです。
③NIO.2
Java 1.0からJavaでファイルを扱うためにjava.io.Fileクラスが提供されていました。
その設計思想が古くなり、いくつかの課題を解決するためにJava SE 7で導入されたのがNIO.2(New I/O ver.2の意)です。
とはいえjava.io.Fileクラスもまだまだ現役ですので、まずFileクラスから扱います。
Fileクラスはディレクトリやファイルへの「パス」を扱います。
Fileという名前ですが、ファイルそのものを扱うわけではないのでFileのインスタンスを生成してもファイルが作成されません。

次のコードのようにFileクラスでは、パスをインスタンスとして生成した後にメソッドでファイルやディレクトリを作成します。
File dir = new File( "/Users/Oishi/java" ); dir.mkdir(); // ディレクトリを作成 File file = new File( dir, "test.txt" ); // Fileオブジェクトと文字列で新しいFileオブジェクトを作成 file.createNewFile(); // ファイルを作成
次にNIO.2です。NIO.2ではパス操作とファイル・ディレクトリ操作が別クラスに分離されました。 パス操作を担うのがjava.nio.file.Pathインターフェースです。 Fileクラスのパス操作よりも出来ることが増えており、例えばtoAbsolutePath()メソッドで絶対パスを取得できます。
Path path = Paths.get( "test.txt" ); // カレントディレクトリのファイルパスを取得 System.out.println( path.toAbsolutePath() ); // /User/Oishi/java/test.txtが表示される
ファイル・ディレクトリ操作を担うのがjava.nio.file.Filesクラスです。 このクラスのメソッドは全てstaticなのでインスタンス化の必要はありません。 引数にPath型オブジェクトを渡すことでファイルやディレクトリを操作します。
Path path = Paths.get( "/Users/Oishi/java/test.txt" ); Files.createFile( path ); // ファイルを作成
copy()、move()、walk()、find()などのメソッドが出題されることが多いように思います。
JDBCによるデータベース連携
②SQL・プロシージャ実行
①DB接続・切断
JDBC(Java DataBase Conectivity)はDB接続・操作のためのインターフェース、例外クラス、全DBMS共通クラスを提供しています。
実際のDB接続・操作はDBMS毎に違うわけですが、各DBベンダがJDBCインターフェースの実装クラスをJDBCドライバとして提供してくれます。

DB接続・切断は、java.sql.Connectionインターフェースが管理します。 このインターフェースの実装クラスはjava.sql.DriverManagerクラスのgetConnectionメソッドを使って取得します。 try-with-resources文を使っているので明示していませんがConnectionはclose()メソッドが必要です。これでDBとの接続が切断されます。
try ( Connection con = DriverManger.getConnection ( "jdbc:mysql://10.0.0.1:3306/data/Sample" ); ) { // SQL・プロシージャ実行 } catch (SQLException e) { throw new RuntimeException(e); }
getConnectionに引き渡す文字列は「接続文字列」と呼ばれるものです。
jdbc:<DBMS種別>://<DBサーバのIPアドレス>:<ポート番号>/<データベースの場所>の形式で指定します。
②SQL・プロシージャ実行
SQLを実行するためのインターフェースがjava.sql.PreparedStatement、ストアドプロシージャを実行するためのインターフェースがjava.sql.CallableStatementです。
ここでもtry-with-resources文を使っているので明示していませんがStatementはclose()メソッドが必要です。
try ( Connection con = DriverManger.getConnection ( "jdbc:mysql://10.0.0.1:3306/data/Sample" ); ) { var selectSql = "select * from items where cd = ?"; var insertSql = "insert into items values ( ?, ? )"; var proc = "CALL UPDATE_ITEM( ?, ? )"; try (PreparedStatement ps1 = con.prepareStatement( selectSql ); PreparedStatement ps2 = con.prepareStatement( insertSql ); CallableStatemant cs = con.prepareCall( proc )) { ps1.setInt( 1, 10 ); // SELECT文のwhere句に値を代入 ResultSet rs = ps1.executeQuery(); // SELECT文を実行 while ( rs.next() ) { System.out.println( rs.getString("name") ); // SELECT結果を出力 } ps2.setInt( 1, 20 ); // INSERT文の変数1つ目に20を代入 ps2.setString( 2, "apple" ); // INSERT文の変数2つ目にappleを代入 ps2.executeUpdate(); // INSERT文を実行 cs.setInt( 1, 10 ); // プロシージャの変数1つ目に10を代入 cs.setString( 2, "banana" ); // プロシージャの変数1つ目にbananaを代入 cs.execute(); // プロシージャ実行 } catch (SQLException e) { throw new RuntimeException(e); }
ここでのポイントは4つです。
- ConnectionのprepareStatement、prepareCallメソッドでStatementオブジェクトを取得。
- setXXXでSQL文の変数(? で定義)に値を代入。インデックスが「1」から始まるのに注意。
- SELECT文はexecuteQuery、INSERT/DELETE/UPDATE文はexecuteUpdate、プロシージャはexecute()メソッドで実行。
- SELECT結果はResultSet型のオブジェクトに格納。next()メソッドで1行ずつ読み取り、getXXXで値を取得。
まとめ
長くなりました・・・これでも範囲のいくつかは省略しています。
今回触れなかった関数型インターフェースやコレクション、ジェネリクスはJava Silverの知識の延長線上でイケるはず。
もし理解できなければJava Silverのまとめ記事の方も見てみてください。
その他にもローカライズやモジュールシステム、アサーション、アノテーションなどがJava Goldの試験範囲ですが、比較的覚えることも出題数も少な目に感じたので今回は省略させていただきました。
現場ではJava単体というよりはSpringフレームワークなどと使うことが多いので、今回の経験をベースにより実践的な知識を身に付けていきたいと思います!