【書評&要約】「入門 監視」の全章をまとめてみる

O'Reillyの紹介文を引用しますと「システムのどの部分をどのように監視すべきか、また監視をどのように改善していくべきかについて解説する書籍」です。本書については既に多数の書評・ブログが存在していますが、自身へのInputも兼ねて全章を横断的にまとめてみます。またAWSエンジニアの端くれとして、各監視項目をAWSで実現する場合のサービスにも触れていきます。
入門 監視 モダンなモニタリングの為のデザインパターン
本の概要
2019年1月に日本語訳の初版が発行されています。著者はMike Julian氏、訳者は松浦 隼人さんです。監視のエッセンスが228ページという短さで、非常に簡潔にまとめられています。どストレートなタイトルですが、その名を冠するに相応しい全エンジニア必読の本です。

本書は、システムのどの部分をどのように監視すべきか、また監視をどのように改善していくべきかについて解説する書籍です。
(中略)監視対象が変化し、システムアーキテクチャが進化する中で、従来から変わらない監視の基本を示しながら、時代に合った監視の実践を解説する本書は、監視についての理解を深めたいエンジニア必携の一冊です。
(出典)O'Reilly Japanの紹介文より
非常に示唆に溢れた本ですが、原著は2017年発行のため、2023年現在で既に6年経っています。ここ数年、オブザーバビリティやSREという単語を耳にすることが多くなり、「監視なんて古いよ」という言葉も聞こえてきそうです。
著者の松浦さんの言葉を借りると「監視とは、高いオブザーバビリティをシステムに対して持たせるために必要な1要素」です。ゆえにオブザーバビリティ主流の現在においても、監視の重要性は依然高いままです。
※上記の言葉は松浦さんの「入門 監視」5年を経て変わったこと、変わらないことという2022年1月の登壇資料からの抜粋です。本書と合わせて、こちらのスライドも見ておくと今時点の監視について知れると思います。
本の構成
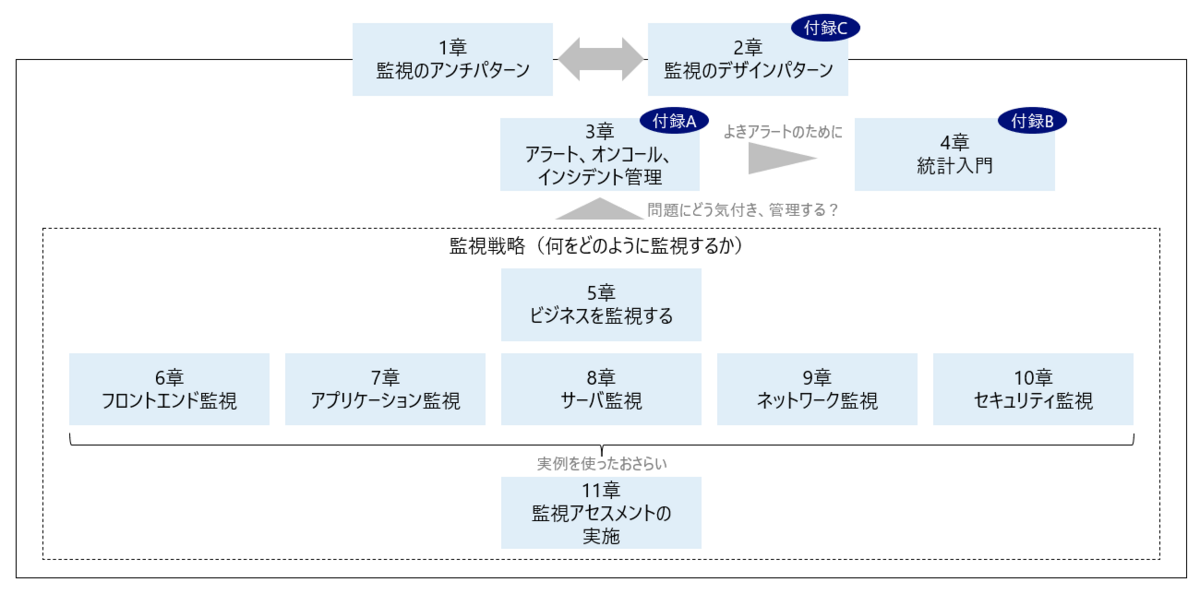
全11章と3つの付録から構成されます。
最初の1章と2章はセットです。1章では、一見よいが実装すると上手くいかない「監視のアンチパターン」を紹介しています。逆に2章では好例の「デザインパターン」に触れます。これらのエッセンスは、この書籍全体のベースです。この2つの章を読むだけでも沢山の示唆が得られます。
3章は監視で何らかの兆候・エラー検知した後の動作である「アラート、オンコール、インシデント管理」、4章はアラートの精度を上げるための統計について触れます。
5~10章が具体的な監視項目です。5章は他よりも一段視座が高いですが、6~10章はシステムのコンポーネント別に監視観点を整理しています。そして最後の11章では、これまでのエッセンスを実例を使って振り返ります。
本書の肝はやはり1~2章でしょう。読者が共感しそうな例をアンチパターンとして取り上げ、その解決策としてデザインパターンを紹介する。その流れで「自分たちの運用がまさにこれだ」「そうすればよいのか!」と読者を惹きつけています(自分もそうでした)。
本の要約
そんな簡潔にまとめてくれている書籍を、さらにまとめてみます。まだ読んでない方には「こういう内容の本なんだな」、完読済の方には「そういう構成だったのか」と思ってもらえるよう各章ごとにエッセンスを図示します。とは言え、どうしても欠落する要素もあるので、そこは本書を読んでしっかり理解してください。
1章 監視のアンチパターン

アンチパターンとは、一見よいアイディアだが実装すると手痛いしっぺ返しを食らうものをいう。 ---- Jim Coplien
1章では、実運用でやりがちだが、上手くいかない例が5つ挙げられています。そのどれもが「自分もやってるな」と思えるものばかりなので、グサリと刺さることでしょう。
特に「パターン2:役割としての監視」は重要だと感じています。一定規模のシステムを運用する場合、監視が特定チームの役割になることがあります。ですが、自分たちが設計・開発していないアプリ、インフラ、ネットワークを適切に監視する仕組みを作ることは難しい、と本書は述べています。監視は役割ではなくてスキル。設計・実装した担当者自身がシステムを監視できるのが正しい姿です。
一方で、チーム横断で使える監視ツールをサービスとして提供する監視チームがいるのはOK、とのこと。その場合もアラートや監視を定義するのは監視チームではなく、アプリ、インフラ、ネットワーク担当の役割です。一定規模のシステム運用の役割分担における、一つの最適解だと思います。
2章 監視のデザインパターン

自分たちの監視における課題を知った後は、どうそれを改善するかに話が移ります。ここでは4つの好例が挙げられています。
「パターン1:組み合わせ可能な監視」は、「アンチパターン1:ツール依存」の対義にあたるものですが、これについて訳者の松浦さんは2022年のイベントで『この5年でフルスタックなツールが増えた』と述べています。確かにDataDogやNew Relic、Dynatraceのようなサービスが洗練され、現場に浸透してきた印象です。原著が発表された2017年とは異なり、多様なツールを疎に組み合わせるよりも、監視したいものに合ったフルスタックな監視ツールを選ぶことが今のデザインパターンと言えそうです。
また「パターン3:作るのではなく買う」については、付録Cで監視SaaSの利点、選定時の考慮点、導入時の具体作業の補足があります。
3章 アラート、オンコール、インシデント管理

3章は監視を使って、どう問題に気付き、その問題をどう管理するかを整理しています。監視とアラートは切り離せませんが、「素晴らしいアラートは、見た目よりも難しい」と本書でも述べられています。その理由は2点。1点目は「4章 統計入門」にも繋がります。
- メトリクスは急激に変化しがち。メトリクスに閾値を設けてアラート設定すると不必要にアラートを出しかねないし、移動平均を使ってならすと情報の粒度が落ちるトレードオフがある。
- アラートの多くは人間が受ける。アラートを受け取りすぎると、人間の注意力は削がれていく。
そこでよいアラートを作るための6つの方法が述べられます。目新しいものではないのですが、いずれも見て見ぬ振りをしがちなので愚直に対応しないといけません。
アラートの中でも「オンコール」は特にチームを疲弊させるため、特化して取扱い方を取り上げています。ここでも「コール数を減らして、ローテーションを組もう」という極めて一般的な策が提示されますが、アラート・オンコールの改善に近道はないということの示唆だと思います。
最後に「インシデント管理」でアラートを受けた後の、問題の管理手順と体制に触れているのも良いですね。ここでも銀の弾丸はなく、担当者間や利害関係者とのコミュニケーションを重視しているのが印象的です。
◆AWSで実現する場合◆
AWSネイティブな機能ならCloudWatch Alarmを使ってアラートを上げることになるでしょう。SNSと連携させることで、メール発信することもできますし、AWS Chatbotに繋げてSlackなどのチャットにメッセージを送ることもできます。またAmazon Connectを使えばオンコールも実装できます。ただ、実現場としてはPagerDutyなどの3rdパーティプラットフォームを使ってオンコールの自動化を実装していることが多い印象です。
Amazon CloudWatch でのアラームの使用 - Amazon CloudWatch
Amazon Connectを活用したオンコール対応の実現 - AWS Black Belt
Amazon CloudWatch でのアラームの使用 - Amazon CloudWatch
Amazon Connectを活用したオンコール対応の実現 - AWS Black Belt
4章 統計入門

3章で触れた素晴らしいアラートには統計学の知識が必要です。最近のモニタリングツールはログ/メトリクスを時系列DBで収集するので、複数のデータポイントに対する統計値を使ってアラートを定義できます。
◆AWSで実現する場合◆
5章 ビジネスを監視する

本書ではここからが第二部。何をどのように監視するのが、より具体的に述べられます。
システムが存在している理由は、ユーザに価値を届けるため、ビジネス目標を達成するためです。インフラを安定稼働させることはその手段にすぎません。2章の「ユーザ視点での監視」というデザインパターンは、より上位の目的に対して監視しようという考えで、その最たるものが「ビジネス監視」です。
そこで本章では、ビジネスを監視するための「ビジネスKPI」の例と、そのKPIを測定する技術的なメトリクスの考え方が示されます。本書で紹介されている技術指標はエラー率とレイテンシです。これは6章のフロントエンド監視や、7章のアプリケーション監視で測定されるメトリクスです。つまり、ビジネス監視は独立した項目ではなく、他の監視を内包する一段大きな監視項目と言えそうです。
◆AWSで実現する場合◆
AWSにおいて、直接的にビジネスKPIの設定・測定を行うサービスはありません。本書でも触れているように、すべてのビジネスはそれぞれ違うので、そのKPIも個々に異なります。ただし、ビジネスKPIをレイテンシ、エラー率といった技術指標に落とし込むことができれば、それはCloudWatchダッシュボードを使って可視化することが出来るでしょう。売上やアクティブユーザ数などのビジネスKPI自身を可視化するならQuickSightを使うことになるかもしれません。またDataDogやNew Relicといったオブザーバビリティツールにも、それらの可視化を支援する機能が提供されています。
Amazon CloudWatch ダッシュボードの使用 - Amazon CloudWatch
ビジネスダッシュボードことはじめ | Observability Platform | New Relic
Amazon CloudWatch ダッシュボードの使用 - Amazon CloudWatch
ビジネスダッシュボードことはじめ | Observability Platform | New Relic
6章 フロントエンド監視
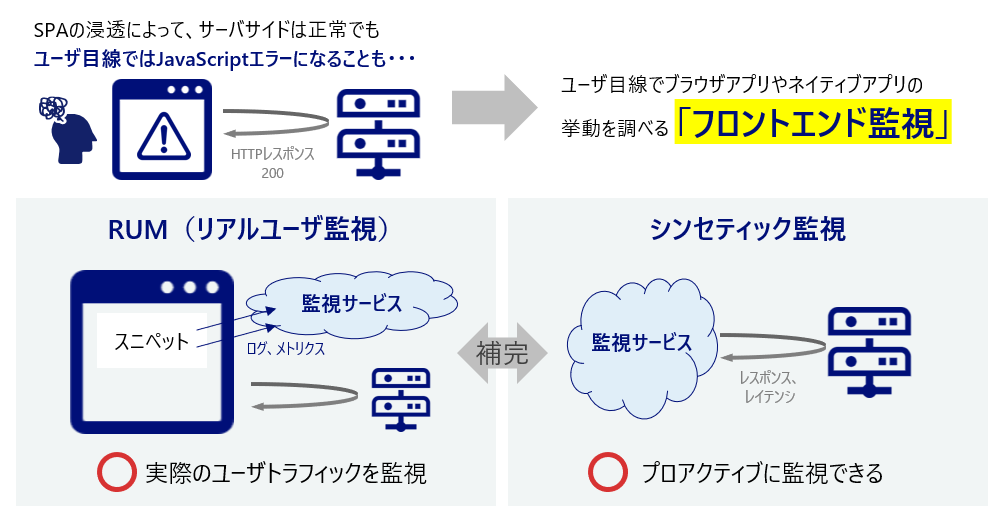
「フロントエンド監視」とは、ブラウザアプリやネイティブアプリの挙動を調べる監視です。SPA(Single Page Application)で実装するアプリが増えてきて、サーバサイドではエラーが起きていないが、フロントエンドではJavascriptのエラーが発生することもあり得るようになり、このような監視が生まれました。実際のユーザから見たロード時間の測定もできます。
手法としては、RUM(Real User Monitering)とシンセティック監視の2パターンがあります。RUMはGoogle Analyticsのように、各ページに小さなJavascript(スニペット)を埋め込み、メトリクスを中央監視サーバに送信する方式です。一方でシンセティック監視は、監視ツールから偽のトラフィックを生成し、システムからのレスポンスをチェックする方式です。本書では実際のユーザが経験しているパフォーマンスを監視するという点で、RUMはフロントエンド監視の仕組みの中心的な存在としています。一方でシンセティック監視は、監視ツールから能動的にトラフィックを発生させるため、プロアクティブな監視が実現できます。これらは補完的な役割を持ち、どちらも実装するのが理想です。
◆AWSで実現する場合◆
AWSにおいては、CloudWatch RUMとCloudWatch Syntheticsというサービスがあります。CloudWatch RUMはJavascriptのスニペットを提供してくれるので、それをフロントエンドアプリに埋め込むとJavaScriptエラーやページのロード時間、ユーザの画面遷移(ユーザージャーニー)を可視化してくれます。CloudWatch SyntheticsはAPIやWebアプリにAWS側からアクセスして、レスポンスの正常性を監視します。
新機能 – Amazon CloudWatch RUM をご紹介 | Amazon Web Services ブログ
CloudWatch RUM を使用する - Amazon CloudWatch
模擬モニターリングの使用 - Amazon CloudWatch
新機能 – Amazon CloudWatch RUM をご紹介 | Amazon Web Services ブログ
CloudWatch RUM を使用する - Amazon CloudWatch
模擬モニターリングの使用 - Amazon CloudWatch
7章 アプリケーション監視
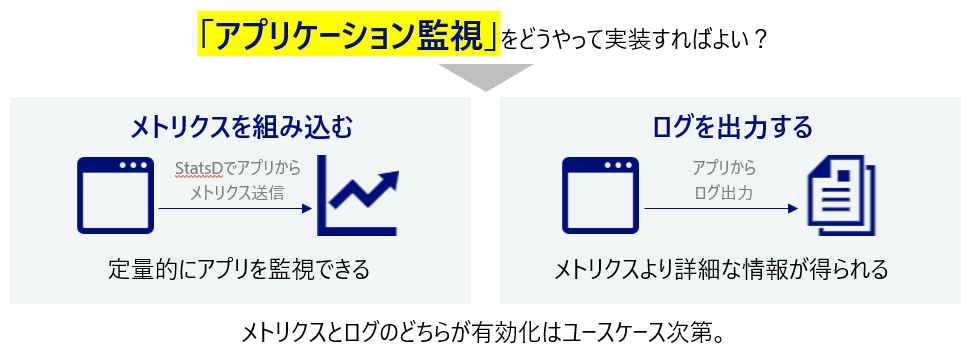
本書で最もページ数が割かれている監視の1つが「アプリケーション監視」です。アプリケーションを監視するのは非常に効果的なのですが、CPU/メモリなどインフラ監視と比べて軽視されがちです。その理由はアプリを監視する数値的指標(メトリクス)を取得するのが難しいからかもしれません。
その解消法の1つとして本書ではStatsDを紹介しています。StatsDはメトリクスを送信するクライアント(=アプリ内に組み込み)と、メトリクスを集約するサーバに分かれます。APIが成功したらクライアントがメトリクスAを、失敗したらメトリクスBをサーバへ送信、という処理をアプリに組み込むことでAPI成功回数/失敗回数といったメトリクスを取得することが出来ます。
メトリクスは定量的にアプリを監視できる反面、各処理がどのような挙動だったかミクロな情報が欠落します。その点、ログを取得しておけばより詳細な情報が得られます。ただ何でもかんでもログ出力するのはアプリ性能に悪影響を及ぼす可能性があります。従ってアプリ監視は、メトリクスにするかログにするか、ログにするなら何のログを取るべきかを検討するがポイントです。
また、マイクロサービスアーキテクチャの場合、個々のサービス単体を監視しても結局ユーザ目線でレイテンシはどうだったのか、等の情報が得るのが難しくなります。そこで各アプリのリクエストに一意なIDを「タグ付け」することで複数アプリを横断した挙動を把握するトレーシングが有効です。
◆AWSで実現する場合◆
AWSだとCloudWatch Agentでアプリケーション監視が実現できます。ログをCloudWatch Logsに送信できますし、CloudWatch AgentがStatsDを内包しているので、メトリクスの取得も可能です。またトレーシングにはXrayが使えます。
StatsD を使用してカスタムメトリクスを取得する - Amazon CloudWatch
AWS X-Ray の概要 - AWS X-Ray
StatsD を使用してカスタムメトリクスを取得する - Amazon CloudWatch
AWS X-Ray の概要 - AWS X-Ray
8章 サーバ監視
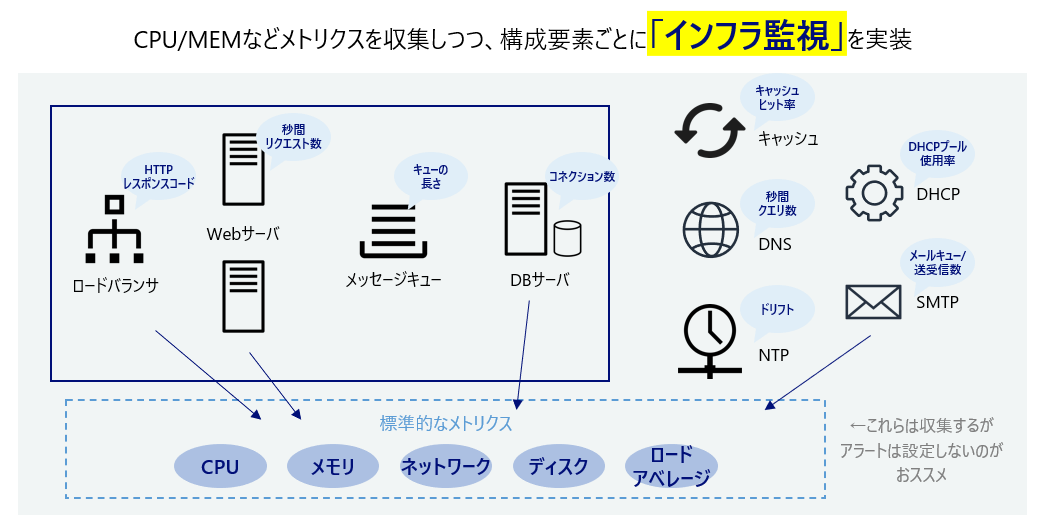
本書では冒頭から「ユーザ視点で監視せよ」と述べているため、ユーザから遠いところにあるCPU・メモリなどのOSメトリクス監視への依存を批判しています。しかし全く無益という訳ではないため、これらのOSメトリクスは収集はしておくもののアラートは設定しないのがオススメだそうです。正直OSメトリクスへのアラート設定をバリバリ定義している身としては「本当にアラート無くて大丈夫?」と思いつつも、深く考えずにとりあえず設定してるアラートもあるなと反省しました。
その他にWebサーバなら秒間リクエスト数やHTTPステータスコード、DBサーバならコネクション数や秒間クエリ数、非同期アプリケーション(Pub-Subシステム)ならキューの長さや秒間のキュー消費数など、代表的なインフラ構成要素ごとに監視観点を述べてくれています。
◆AWSで実現する場合◆
ここでもCloudWatch Agentで情報を収集し、CloudWatch MetricsやCloudWatch Logsで管理することになるでしょう。またWebサーバの前にALBを配置すればリクエスト数を自動取得してくれますし、SQSを使えばキューの長さなどのメトリクスが取得されます。RDSならPerformance InsightでDB負荷に関する情報を確認できるので上手くマネージドサービスを使いたいですね。
Application Load Balancer の CloudWatch メトリクス - Elastic Load Balancing
Amazon SQS で利用可能な CloudWatch メトリクス - Amazon Simple Queue Service
Application Load Balancer の CloudWatch メトリクス - Elastic Load Balancing
Amazon SQS で利用可能な CloudWatch メトリクス - Amazon Simple Queue Service
9章 ネットワーク監視
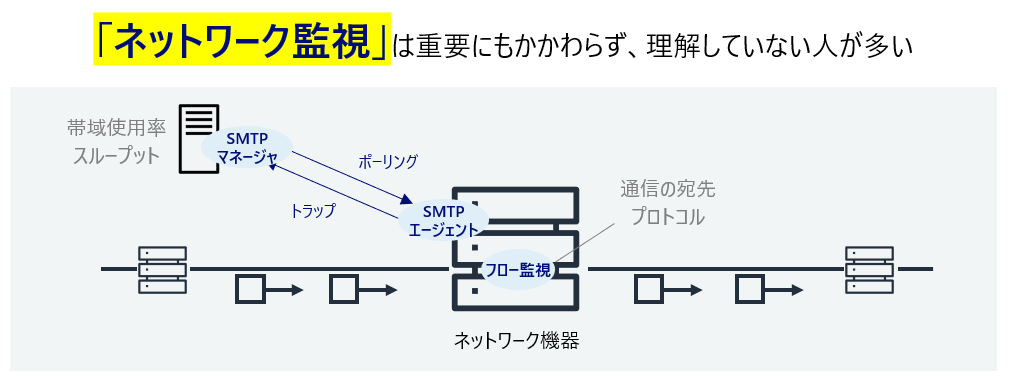
ネットワークの可用性が低ければ、アプリケーション自体の可用性も低くなってしまいます。パフォーマンス面でも同様のことが言えるため、ネットワークは非常に重要な要素である一方、かなり専門的な領域であるため、多くの人が深く入り込みきれていないと思います。私もそんな1人で、この章は理解するのが難しかったです。
ルータやスイッチなどをネットワーク機器を監視するには、SNMPを使うことが多いそうです。SNMPマネージャの機能を持ったサーバから、SNMPエージェント(=ルータなどのネットワーク機器)に対して情報をリクエストしレスポンスを受けるポーリングと、何らかのイベントを契機にエージェントが能動的にマネージャに通信するトラップがあります。SNMPを使うことで帯域幅の使用率やスループットを計測できます。
またCiscoやJuniperなどのベンダはNetFlowやsFlowという機能を使ったフロー監視をサポートしています。フロー監視を使えば、どこからどこに対して何のプロトコルで通信されたのかという情報が取得できます。
◆AWSで実現する場合◆
AWSではルータ・スイッチといったネットワーク機器を管理する必要が無いため、SNMPによる監視は必要ないかもしれません。一方で、VPC Flow Logsを使えば各ENIのフロー監視ができます。サーバ間の疎通が取れないときなどVPC Flow Logsが有効なケースがある上に、後述のGuardDutyなどのインプットになっているため、取得が推奨されています。
VPC フローログを使用した IP トラフィックのログ記録 - Amazon Virtual Private Cloud
VPC フローログを使用した IP トラフィックのログ記録 - Amazon Virtual Private Cloud
10章 セキュリティ監視

アプリやインフラは必要なメトリクスを取得するように事前定義されることが多く監視しやすいのに対し、セキュリティを考慮して実装しておらず、セキュリティ監視を行う手掛かりすら無いことがあります。そこでこの章は監視方法というよりは、どうやってセキュリティを実装するかという観点になっています。
まず監査ログを取得し、いつ、誰が(何が)、どんな操作をしたのか情報を残すことです。本書ではLinuxにおけるauditdが紹介されています。
ホスト型侵入検知システム(HIDS)は、特定のホスト上で不正な行為を検知する仕組みで、McAfeeやSymantecのように監視対象のサーバ内にエージェントをインストールします。ネットワーク型侵入検知システム(NIDS)は、流れるネットワークを監視して不正な通信があれば検知します。本書ではHIDSの例として、rkhunterが紹介されています。
◆AWSで実現する場合◆
AWSにおける監査ログはCloudTrailで取得します。これによりコンソールやAPI経由で誰がいつ何の操作を行ったのか記録を残せます。HIDSは3rdパーティ製品をサーバに導入するのが素直だと思いますが、下記リンクのように自前で構築することも選択肢としてはあります。NIDSとして簡易に導入できるのはGuardDutyです。またAWS Network Firewallを使えば個別のルールを適用させてNIDSを実現できます。
Amazon EC2インスタンスにホストベースの侵入検知システムアラートの監視方法 | Amazon Web Services ブログ
AWS Network Firewall が AWS マネージドルールのサポートを開始
Amazon EC2インスタンスにホストベースの侵入検知システムアラートの監視方法 | Amazon Web Services ブログ
AWS Network Firewall が AWS マネージドルールのサポートを開始
11章 監視アセスメントの実行
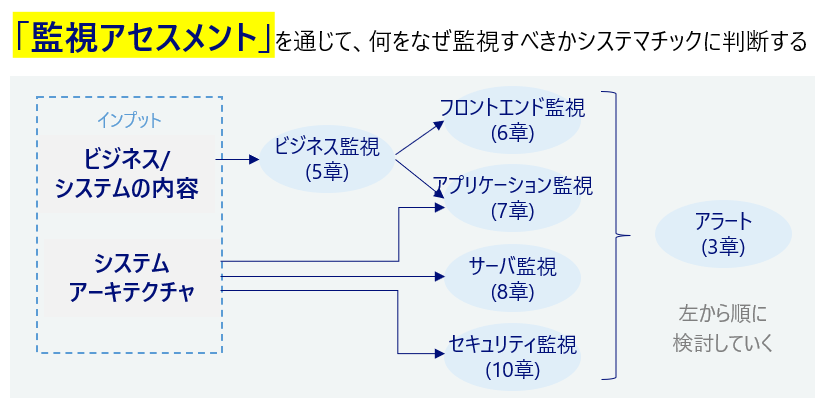
これまでの振り返りの章です。Tater.lyというレストランのレビューサイトを例に、ビジネス監視(5章)→フロントエンド監視(6章)→アプリケーション監視(7章)→セキュリティ監視(10章)→アラート(3章)の検討ポイントを列挙しています。具体例を使ってこれまでのおさらいが出来ます。
まとめ
簡潔にまとめるつもりが、1万文字以上の大作となってしまいました。途中何度も「複数の記事に分割したほうが良いかも」と思いながらも、一覧性にこだわって敢えて1つの記事に集約させました。ここまで読んでくださった方は、本当にありがとうございます。
本書は非常に濃厚な内容をぎゅっとまとめているため、1つ1つの章がサクサク進んでいきます。それが故にさらりと読み通してしまい、全体の構成が腹落ちしなかった方にとって、理解を深める一助になればよいなと思います。